端的に言うと性能が良いからです。
これを理解するにはバッファプールへの理解が必要です。ディスク指向のデータベースの上では有限のメモリを最大限活用することでメモリに入り切らない巨大なデータ群に対して良好な参照性能を出す必要があります。バッファプールとはディスク上のデータの羅列を固定サイズのページ(InnoDBの場合16KB)の羅列であるとして読み書きに必要な分だけをメモリに移し取り複数の書き込みをできる限りメモリ内で受け止めて後でまとめてディスクに書き戻すという、ライトバック型のキャッシュのような機構です。

この中においてバッファプールは有限のサイズしか無いので適宜プール内のデータを書き戻して入れ替えながら上手くやっていく必要があります。
さてB+treeとB-treeの最大の違いは木のリーフ以外の部分(ブランチノードやインターナルノードと呼びます)にキーに対するバリューを保存するかどうかです。そしてノード1つはバッファプールで管理される1ページを保持しています。ページサイズが同じならB-treeはブランチノードの中にキーに加えて値の実体も保存する必要があるのでブランチノード1つが保持できる子ポインタの数は自ずと少なくなります。対するB+treeはキーに対応する値を持たず子ノードのポインタだけを持てばいいのでブランチノードが保持できる子ポインタの数はB-treeより多くなります。下図参照↓
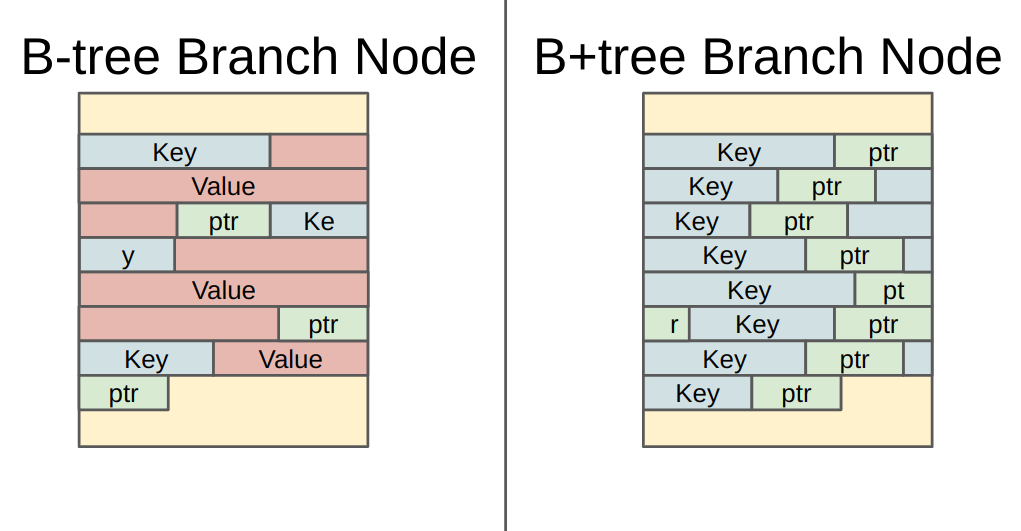
これによってB-treeは探索が木の途中で終わる可能性もある一方で木全体は個々のノードの小ポインタが少ないせいで高くなりがちでB+treeは木が低く抑えられます。データベースとしては検索対象のデータが常に全部バッファプールのメモリ内に収まらないという前提があるのでページのいくらかはディスクに置いたままにして、メモリの速度を最大限活かす必要があります。
さて下にB-treeとB+treeを模式しました。B+treeの方が子を多く持てるので3〜4の子ノードを持ちます。B-treeは子ノードを持てる数が少ないので2ページを子として持ちます。赤のページがメモリに載っているページで同時に5枚までしかメモリに載らないとします、黄色のページがディスクにしか無いページでその読み出しには多大なコスト(HDDの場合10ミリ秒、3GhzのCPUにとって3000万クロック!)がかかります。B+treeはブランチノードがおよそずっとメモリに載り続ける仮定ができます。B-treeはルート含めどのページにも目当ての値が保存されている可能性があります。
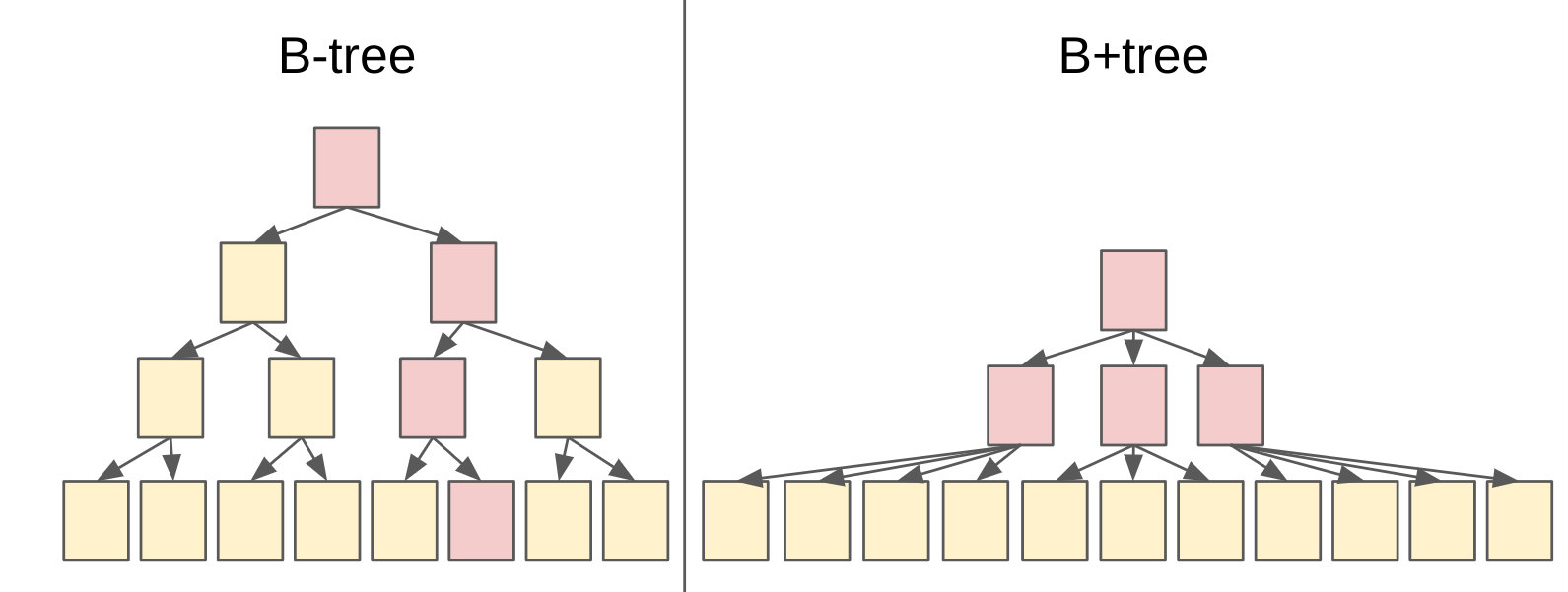
B+treeはどの値を読むときも常に確定で1回のディスクシークが必要ですが、メモリに乗り切らないデータを扱う以上は避けられないコストであります。B-treeは運が良ければメモリだけで値を返せる可能性もありますが最悪の場合はディスクシークが3回になります。しかも目的のページを運良くキャッシュできている可能性はディスクとメモリのサイズ比が広がる程に悪化していってしまいます。そのページに目当ての物があった場合のディスクシーク回数の回数を書き足すと以下のようになります。

B-treeは全部で15枚あるページに対して期待値1.53回(=23/15)のディスクシークでアクセスできます。B+treeは常に1回です。B+treeの方が少ないディスクシークと言えます。ハードディスクがとにかく遅い時代の設計なのでそれと比べるとツリーを辿ることのCPUコストは無視して論じる事が出来ます。
とここまでが古典的データベースの話ですが、最近は結構事情が違います。近年では
MySQLにアクセスするデータは99%以上バッファプール上のデータに当たるまでシャーディングなどでチューニングする事が良くある
メモリの価格が劇的に安くなったのでメモリに乗り切らないデータは扱わないと初めから割り切ったインメモリDBも台頭
何なら世の中のDBの9割は5GB未満しか保存していないなんて与太話もある
ディスクシークはNVMeでめちゃくちゃ速くなったのでデータベースアクセスの支配項が移った
構造上ブランチとリーフに多重で同一のキーが保存されるB+treeはキーが長い文字列や複合キーなどによって複雑に長くなった場合に無駄が多い
など、MySQLが設計された頃とはハードウェアや使い方の様子が大きく様変わりしているので今後またB+tree以外のデータ構造にも脚光が集まるシーンが来るのではないかと期待しています。