単純にNVIDIAのGPUの方がチップあたりに多大なコストを掛けているお陰と認識しています。ここでそれぞれの一般向け市販品のハイエンド製品を見てみましょう。
コンピューティングユニット数や周波数などは作りや考え方によって違うため比較不能な一方で、比較しやすいのはトランジスタ数です。
RTX 4090: 76,300 million
RADEON 7900: 57,700 million
NVIDIAの方が32%多く、そのベンチマーク性能は20%上です。一般にトランジスタ数を増やすほどよりいろんな事ができますしプロセッサの数も増やせるので高い性能を達成しやすいですが、単純に倍のトランジスタを使えばピッタリ倍の性能になるほど単純でもないので(アムダールの法則などで検索してください)これぐらいの差は想定の範囲内です。
質問者さんの仰るとおり、最適化などは共通化可能でどちらか片方のメーカーが同程度のトランジスタで圧倒的に高い性能が出せるような秘密を隠しているわけではありません。目的を絞れば、例えば行列演算に特化した専用回路(Tensor Core等と呼ばれています)を使う事でトランジスタあたりの性能を高める事はできますがそれ以外の目的には使えないので別のベンチマークでは不利になります。
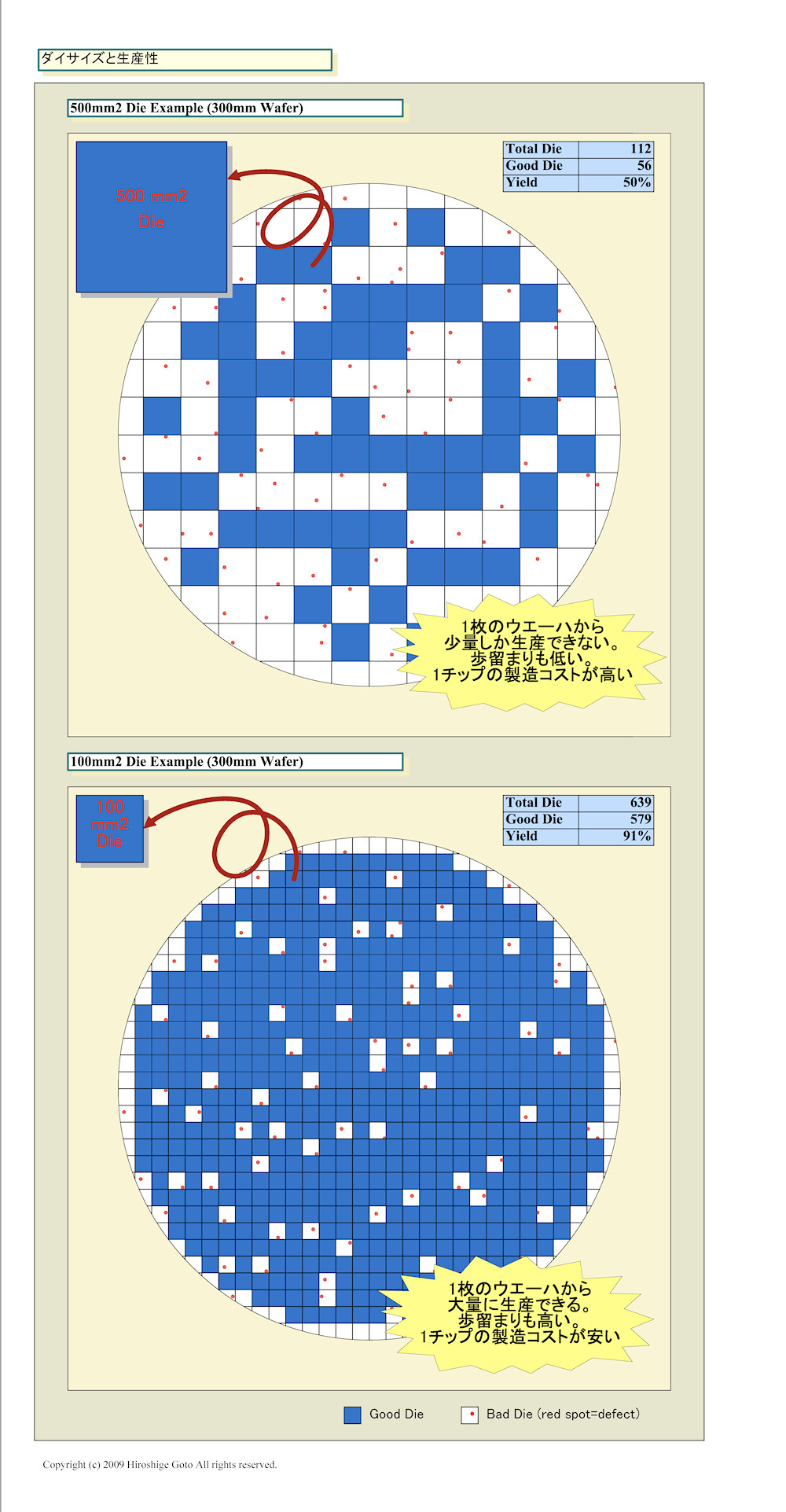
ですので性能競争でデッドヒートしていく上で、高いチップ性能を叩き出すためにはより大きな面積のチップを用意してトランジスタをぎっしり詰めて行くのが基本戦略になるのですが半導体製品は倍の面積のチップを作る為に掛かるコストは倍以上に膨れ上がる性質があります。基本的に半導体はシリコンの円盤の上に焼き付けた回路を量産して運良く欠陥が無かった物を製品化する、という方法で製造するのですが1枚のチップの面積が広がる程にチップ内に欠陥が含まれる可能性が上がるからです。この記事にある図がわかりやすいかと思います。
なぜNVIDIAのGeForce GTX 480はプロセッサ数が減ったのか
そこで面積を比べると
RTX 4090: 608 mm²
RADEON 7900: 520 mm²
と、NVIDIAの方が16%ほど大きいです。しかもAMD側の賞味のGPU部分のサイズは300 mm²でおよそ半分以下です(AMD側は歩留まり向上の為にGPUとキャッシュ&メモリインタフェースのダイを別で作って1つのチップに乗せる戦略を取っています)。しかもプロセスサイズで見比べるとどちらもTSMCなのですがNVIDIAは4nm、AMDは5nmと20%も違います。ここは小さいほうが高コストかつ高性能と言われています。
ですので1GPUでいうとNVIDIA側の方が圧倒的に高コストが掛かっている事がわかります。NVIDIAは会社としてこの方針に舵を切ってから長いので、チップ内の欠陥の対処のノウハウ(欠陥のある箇所だけオフにしても動かせるよう内部が冗長化されている等)が貯まっており、巨大チップを作る事に長けていると言われています。
質問に対する僕の答えは「NVIDIAの方が歯を食いしばって最先端プロセスで大量のトランジスタを詰め込んでいるので高性能な事が多い」です。