自作RDBMS、とても楽しいですね。僕が手遊びに書いている物もSS2PLを採用しています。
作る以上は高速であって欲しいというのは自然な願望ですが、実装規模もそのために必要な知識も広範に渡るので、そもそも自分が何を求めてRDBMSを作っているかというゴール設定を意識することが大切です。MVCCの原理を理解するために作るというのも立派なゴールですが、速度のみを求めていくとどうしても構造が汚くなりがちで、その一方で速度を望まないなら何故MVCCを選ぶのかというあたりで苦悩することになるのが人気のなさの一因なのではないかと思っています。
Multi Version Concurrency Control(MVCC)は複数バージョンを作る並行制御手法全般を指しており、その内部では多くの分岐があります。単バージョンしか使わない並行制御はTwo-Phase Lock(2PL)の他にもOptimistic Concurrency Control(OCC)とかTimestamp Ordering(TO)とかSerialization Graph Testing(SGT)といった手法があることはご存知かと思いますが、それぞれにMulti-Version版があり、それぞれMV2PL、MVOCC、MVTO、MVSGTという名前が付いており全部MVCCの仲間です。更にはGoogle SpannerはRead Only Multi Versioning(ROMV)という手法を採用しています。
PostgreSQLやMySQLで使われているMVCCはこの中でもMV2PLを採用しています。
An Empirical Evaluation of In-Memory Multi-Version Concurrency Control という論文の中の一覧表が興味深かったので引用するとこのように商用のデータベースでも細かく実装上の設計判断が異なっている事がわかります。
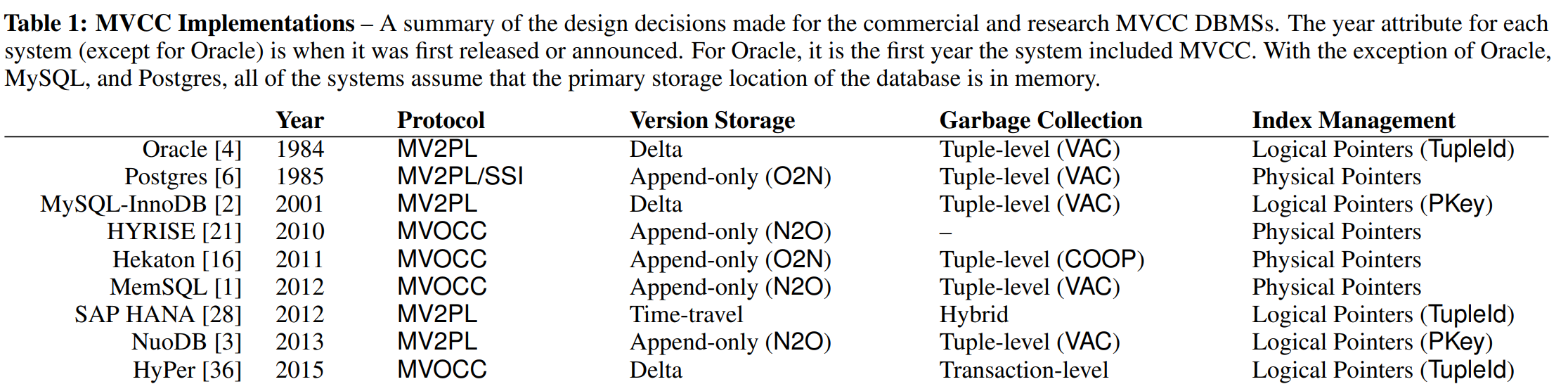
最良の設計判断を探るだけでもいっぱい実装&比較ができてお得ですね(嘆息)論文中ではそれぞれの設計ポイントの詳細と良し悪しに付いて個別に論じているので一読の価値があります。
さて本題に戻りますと、手習いのためにMVCCを実装してみる話として、MV2PLは要点をかいつまめばそこまで難しくはありません。初学者向けの実装の仕方としては、カーネギーメロン大学のAndy Pavlo先生の公開資料が大いに役立ちます。MVCCのためだけに1コマ割いていて授業動画も字幕付きで見れますのでぜひお楽しみください。実際にCMUの学生は彼の授業を聞いて実装してくるそうです。
以下僕からの箇条書きです。
In-Memory型のDBにしましょう。Disk-Oriented型だとバッファプールを用意したりページから溢れた物を処理したりしているうちにそちらの実装の労力が大きくなってMVCCに至るのが遠くなります。
コミットのたびにインクリメントされる単一のグローバルなバージョンクロックを用意し、全トランザクションは開始時か初回の読み書きのタイミングでそれを読んで自身のトランザクション番号を決定します。
MVCCの重要なポイントはReadとWriteが物理的に衝突しないように回避する事です。すべての値には単調増加するバージョン値を割り付け、更新のたびに増やします。Write-Lockは取るべきですが書き換えは物理的にその場所では行わず、新しいバージョンを作る形で実装しつつ、古いバージョンが可視であり続ける事が大切です。自身のトランザクション番号より大きなバージョン番号を読まないよう走る事でRead onlyなトランザクションが絶対にアボートされないで動くように設計しましょう。
ロックとラッチは別物として扱いましょう。ロックはトランザクションの一貫性を守るための論理的なガードであり端的にはロックテーブル上のエントリです、ラッチは並行処理上での物理衝突を避けるためのMutexなどの事を言います。MVCCといえど値を読むときは常にラッチを取ります(そして読み終わったら即座に開放します)ReadとWriteが同一のラッチの上で衝突する場合は後から来た方は待たせて構いません(これはReaderがブロックされた事に数えません)。Write同士はロックの上で調停をしましょう、つまりラッチと違ってコミット時までロックを握りっぱなしにしてください。
自分が読んだ値に対して後から他のトランザクションが書き換えた場合、厳密にはSerializableな実行結果にならない場合があります。コミット時に自分が読んだ値を確認して不一致であればSerializable違反を疑ってアボートする実装もありえますが、気にせずコミットしてもSnapshot Isolation分離レベルに落ちるだけですので、これをもってしてMVCCと呼ぶのは学術的に正しいです。不要なアボートを避けながらSerializableな実行を行う合理的な確認方法としてSerializable Snapshot Isolation (SSI) という物もありますが、手習い目的であればそこまで踏み込むのは先送りで構いません。
いつ古いバージョンを消しても良いか、という問題を先送りにし続ける事で厄介な問題に触れずに実装することができます。全スレッド中の最古のバージョンから見ても永久に読まれる機会が無い古いデータは好きなタイミングで消すことはできますが、その判定はやや面倒です。ベンチマーク等で必要になるまでは古いバージョンがどこまででも残っても動く実装を目指しましょう。コードが綺麗に保たれますし、いざ実装した時にmalloc/freeがいかにボトルネックになるかを痛感できるかと思います…(個人の感想です)
以上、役に立ちましたら幸いです。また気軽に質問してください。