まずログ構造化ストレージというのはアルゴリズムの一種であって特定のハードウェアやデバイスの事を指しません。また、ログ構造化というテクニックに関して言うとSSDの内部でフラッシュメモリのコントローラが利用するケースやブロックデバイスが使うケース(e.g. Log-Structured Block Device)やファイルシステムが使うケース(e.g. RFS)やデータベースライブラリが使うケース(e.g. LevelDB)など様々あります。
永続性と応答速度を両立しようと思った時に一旦書ける場所(ログ)に書いてしまって完了を報告し、後で正しい場所に書き直そうという戦略はジャーナリングなどとも呼ばれ、様々なレイヤーで古くから活用されてきました。しかしそれだと最低でもWrite Amplifier(論理書き込み1回に対して物理書き込みが何回起きるかという倍率)が常に2を超えてしまってスループットが犠牲になります。なのであわよくばログに書いたまま書き移す事なくメタデータを工夫して参照の際にうまく取り回す事(構造化)でどうにか性能のバランスを取ろうというのがログ構造化ストレージの基本思想です。
しかし前述したようにあらゆるレイヤーで似たような事を多重に行うのはあからさまに無駄が多いのでそれを解決するためにはアプリケーションからデバイスまでで一貫した戦略をとったら良いんじゃないか等と研究(e.g. Don’t stack your Log on my Log)されており目が離せない分野です。例えば必ずSSD上でしか動かさない前提のシステムであればファイルシステムやアプリのレイヤーで書き込みをシーケンシャルにするよう拘る意義が薄れますし、DBアプリから見たストレージシステムの方で書いたデータがフラッシュメモリに書かれるまでを垂直統合して最適化したら良いんじゃないかなんて過激な研究もあります。
https://dl.acm.org/doi/10.1145/3514221.3526188
さてストレージのヘッドの話に興味があるようなのでHDDの話をしたいのだと思います。複数のプラッタを持つHDDはプラッタの枚数に比例して読み書きヘッドが増えるので「読み書きヘッドが複数ある」とは言えますがそれらは独立して動くことはないのでスループットには関係ありません。
HDD上のLSM-Treeの上で読み込みが発生して問題ないかというと、もちろん悪影響があります。ちなみに書き込み命令と読み出し命令が複数個キューに積まれた時、それをどの順序で最終的に実行するかは下のレイヤーでうまくディスクヘッドのシーク量が少なくなるよう並べ替えて実行されます。なので最終的に読み書きがどういう順序で実行されるかに付いてはアプリのレイヤーからは制御しきれません。
https://en.wikipedia.org/wiki/Native_Command_Queuing
シーケンシャルな領域への書き込み命令自体が連続している場合はヘッドの移動は最小になるためもちろん最良の性能が出ますし、readが入るとヘッドシークに約10msかかるので書き込みのスループットにも悪影響は出ます。と言ってもLSM-Treeの書き込みのスループットは最良ケースであってもマージ操作の際にガタ落ちするのでReadによる外乱はそこまで致命的ではないと思っています。SSD等であればなおさら影響は減ります。
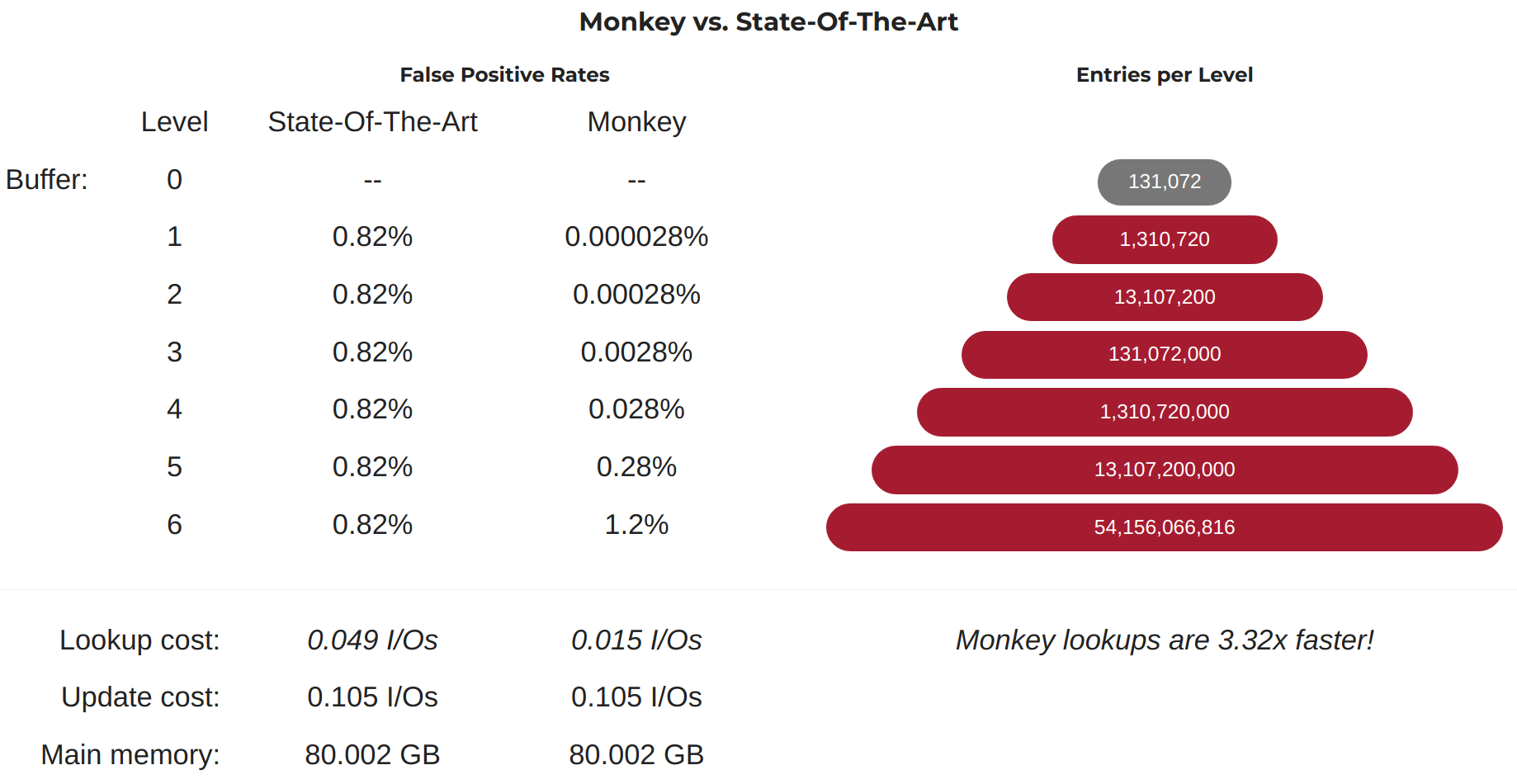
LSM-TreeのReadに関してはメモリを使ってキャッシュするのが基本戦略です。メモリ内の問い合わせによってヘッドシークの回数を減らせば減らすほど良いのでBloom Filterを用いて不在判定を高速に行うのが定番です。LSM-Treeの各レベルごとにBloom Filterを取り付けておき、不在判定に失敗した場合はそのレベル内のペイロードの実スキャンを行うのですが低レベルでの不在判定ミスは高レベルでの不在判定ミスよりペナルティが大きいので低レベルのBloom Filterサイズに傾斜をつけて大きめの容量を振っておけば全体としてスループットが上がるというMonkeyなんかは面白かったです。
http://daslab.seas.harvard.edu/monkey/
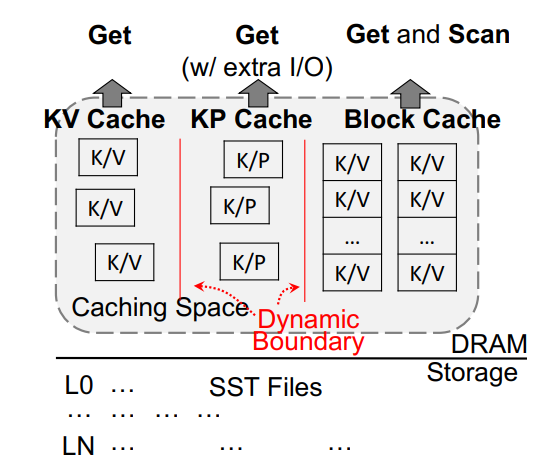
他にも、キャッシュする際にはkeyに対するvalueのポイントクエリの結果をLRUキャッシュなどに入れておいてもレンジスキャンの際にそのキャッシュ内容をうまく活かせれないのでレンジスキャン用キャッシュとポイントクエリ用キャッシュを適応的にバランスさせながらキャッシュメモリの有効活用を試みるAC-Keyなんて研究もあります。
https://www.usenix.org/conference/atc20/presentation/wu-fenggang
https://www.usenix.org
何にせよメモリを使えば使うほどRead性能が上がるという点で難しいトレードオフがあります。LSM-Treeに興味があるのであれば僕のブログ記事もあなたの知的好奇心をくすぐるかも知れません。
https://kumagi.hatenablog.com/entry/end-of-freezing-lsm-tree
以上参考になりましたら幸いです。